Objektum-relációs leképezés a .NET framework segítségével
Erdélyi Tibor (lancelot@inf.bme.hu)
Smulovics Péter (szoke@inf.bme.hu)
Konzulens: Charaf Hassan (hassan@avalon.aut.bme.hu)
BME, Automatizálási és Alkalmazott Informatikai Tanszék
Absztrakt: A különbözõ relációs adatbáziskezelõ rendszerek napjainkban igen elterjedtek, azonban használatuk a hasonlóan népszerû objektumrientált nyelvekbõl még nehézkes. Azok a technológiák, melyek az objektumorientált nyelv mellett egy keretrendszert is szolgáltatnak (JAVA, .NET framework) egy magasabb szintû absztrakciós szintet is nyújthatnának a fejlesztõk számára. Ennek köszönhetõen mind a tervezés mind a fejlesztés folyamata gyorsabbá válhatna, egyes futási idejû hibák elkerülhetõek lennének, végül a módszer áttekinthetõbb, kezelhetõbb forráskódot eredményezne.
Elõadásunk célja rámutatni a módszerben rejlõ lehetõségekre, illetve ismertetni azon problémákat melyekkel egy jelenleg készülõ ilyen rendszer fejlesztése kapcsán találkoztunk. Ezen keretrendszer - elképzelésünk szerint - perzisztens objektumok kezelését tenné lehetõvé, míg a bennük lévõ adatokat egy relációs adatbázisban tárolná. Az implementáció a .NET framework-re épül, és az SQL Server 2000 adatbáziskezelõt használja.
Bevezetés
A szoftverfejlesztés fejlõdésével egyre inkább jelennek meg az olyan technológiák, melyek a perzisztencia kezelésére vagy nem relációs adatbázis-kezelõt használnak, vagy csak magasabb szintû felületet nyújtva használják azt a háttérben. Ez nem véletlen, hiszen az objektum orientált szemlélet lényegesen eltér a relációs adatmodelltõl. Ennek ellenére az esetek 99%-ában mégis valamilyen objektum orientált fejlesztõkörnyezetet és relációs adatbázis-kezelõt alkalmaznak.
Persze a relációs adatbázisok kezeléséhez különbözõ „objektum orientált” interfészek léteznek, mint az ODBC (Open Database Connectivity), a JDBC (Java Database Connectivity) vagy az ADO (Active Data Objects). Mindezeknek közös problémája, hogy a különbözõ wrapper osztályok segítségével csak azokat az alacsony szintû szolgáltatásokat vehetjük igénybe, amiket a relációs adatbázis-kezelõ a query-ken keresztül biztosít a számunkra. Ezért az objektumorientált és a relációs szemlélet közötti különbségbõl adódó nehézségeket a programozónak minden esetben magának kell kezelnie. Ez fölöslegesen nagy feladatot állít a fejlesztõ elé, így kevésbé tud magára a megoldandó feladatra koncentrálni.
Az elmúlt pár évben különbözõ módszerek kezdtek elterjedni a probléma megoldására. Azokban az esetekben, ha összetett, változatos szempontok szerinti lekérdezésekre nincs szükség, a probléma tökéletesen megoldható az objektum orientált adatbázis-kezelõk használatával. Ellenkezõ esetben a legelterjedtebb megoldás jelenleg a java entity beanek alkalmazása, ahol a perzisztencia kezelésének módjától függetlenül használhatunk perzisztens objektumokat. Ebben az esetben viszont ezen perzisztens osztályok megvalósítása a hosszadalmas feladat. Pedig azok a technológiák, melyek az objektum orientált nyelv mellett egy keretrendszer is tartalmaznak – mint a java virtuális gép vagy a.NET framework – ennél sokkal nagyobb automatizmust is lehetõvé tehetnének.
Perzisztencia réteg
Mivel a piacon igen jó relációs adatbázis-kezelõk kaphatóak, ezért nem lenne célszerû a perzisztencia kezelését teljesen új alapokra fektetni. Ezekben a rendszerekben ugyanis minden alapvetõ mûvelet, amire szükségünk lehet már igen hatékonyan implementálva van. Az egyetlen problémájuk a belsõ, tisztán matematikai alapokon nyugvó felépítést követõ, alacsony szintû interfész. Ez a probléma azonban kiküszöbölhetõ, ha az adatbázis és az alkalmazás közé egy olyan speciális perzisztencia réteget helyezünk el, amelyik az alkalmazásban objektumként reprezentált perzisztens adatokat automatikusan áttranszformálja a relációs adatbázis entitásaira, mind lekérdezéskor mind létrehozáskor és módosításkor.
Ezen réteg megvalósítására pedig kiváló eszközül szolgál a java virtuális gép vagy a .NET framework. Ezek segítségével ugyanis az egyes osztályok illetve a belõlük létrehozott objektumok futási idõben kezelhetõek. Így felderíthetõek (reflection), hogy az egyes osztályoknak milyen tagváltozóik vannak. (Ezen tagváltozókra a következõkben a mezõ kifejezést fogom használni, mert az attribútumok a .NET framework esetén mást jelentenek.) A felderített mezõk a nevük alapján már egyértelmûen hozzárendelhetõek az adatbázis entitások mezõihez, azok értéke egy lekérdezés alkalmával automatikusan beállítható, illetve beszúráskor és módosításkor pedig a relációs adatbázis módosításához felhasználható.
Egy ilyen köztes réteg alkalmazása sokkal elõnyösebb annál, mintha – a hagyományos megoldásnak megfelelõen – query-ket ágyaznánk statikusan a forráskódunkba:
Mivel az objektum orientált szemlélet sokkal közelebb áll az emberi gondolkodáshoz, ezért a fejlesztés a programozó számára lényegesen egyszerûbbé válik.
Az adatbázis és az alkalmazás felépítése ugyan azt a szemléletmódot tükrözi, ezért a perzisztencia kezelése szerves részévé válik az alkalmazásnak, így az integráció sokkal áttekinthetõbb.
Az adatbázis leírása típusos osztályokban is elõáll. Ennek köszönhetõen sok futási idejû hiba elkerülhetõvé válik. Ez különösen elõnyös az adatbázis utólagos módosítása esetén. Hiszen az egyes futási idejû hibák helyett – melyek egy része csak bizonyos feltételek teljesülése estén következik be, így felderítése nagyon nehéz – minden a módosításból fakadó hiba a feltételektõl függetlenül már fordítási idõben kiderül.
A fejlesztés idõtartama lecsökken, az elékészült forráskód pedig áttekinthetõbbé, strukturáltabbá válik.
Mindezeknek köszönhetõen rövidebb idõ alatt, olcsóbban egy jobb minõségû, könnyebben módosítható szoftvert készíthetünk el.
Objektum-relációs leképezés
Az objektum-relációs leképezésnek két megközelítése létezik. Egyrészt definiálhatjuk egy meglévõ relációs adatbázishoz az objektum orientált megfelelõjét, másrészt pedig hozzárendelhetjük egy osztály-hierarchiához a megfelelõ relációs adatbázist. Ez a cikk kizárólag az utóbbi esettel foglalkozik.
Igen kézenfekvõnek tûnik, hogy az osztályokat a relációs modell egyes entitásainak feleltessük meg, azaz minden osztályhoz egy külön táblát rendeljünk az adatbázisban. Ha az öröklõdéstõl eltekintünk, akkor ez a megfeleltetés helyénvaló. A származtatott osztályok azonban nem tekinthetõek teljesen különállónak az alaposztályoktól. Mivel az öröklõdés fogalma teljesen hiányzik a relációs modellbõl, ezért azt a entitásokra és közöttük lévõ kapcsolatokra kell visszavezetnünk. Erre különbözõ módszerek léteznek, melyekre a késõbbiekben még részletesen kitérünk.
Az öröklõdés reprezentációjának bármelyik módját is választjuk, végeredményben mindegyik osztálynak egy entitás fog megfelelni (esetleg az absztrakt osztályoknak nem). Ennek megfelelõen a konkrét példányok az entitás példányokkal, azaz az adatbázis táblák rekordjaival lesznek egyenértékûek.
A mezõk az egyes objektumok egymástól különbözõ tulajdonságait, azok állapotait írják le. Ezek triviálisan megfeleltethetõek az entitások mezõinek, és ennek megfelelõen a táblák oszlopainak. Egyes esetekben azonban szükségünk lehet arra, hogy az objektum orientált leírásban magukhoz az osztályokhoz, mezõkhöz rendeljünk statikus információkat. (Például hogy a relációs adatbázisban elõforduló kényszereket, indexeket, mezõhosszakat, stb. le tudjuk írni.) Ennek a célnak tökéletesen megfelelnek a .NET framework attribútumai, melyek éppen ilyen statikus metaadatok definiálását teszik lehetõvé.
A kapcsolatok kezelése nagyon eltér a két szemléletmódban. A relációs modell külön relációban felelteti meg egymásnak az entitásokat, míg az objektum orientált szemlélet az asszociáció két oldalán külön-külön teszi lehetõvé a navigációt. Ezt a különbséget a perzisztencia rétegnek teljesen átlátszóan el kell rejtenie a fejlesztõ elõl, ami annál is inkább bonyolult feladat, mivel a relációs adatbázisban a kapcsolatok kardinalitásuktól függõen más és más módon vannak reprezentálva:
Egy-egy kapcsolat esetén az egyik entitás tartalmaz egy külsõ kulcsot, ami a másik entitásban elsõdleges kulcs. Ha az osztályok közül is csak az egyik tartalmazna referenciát a másikra, akkor a navigálás a másik irányba nem lenne lehetséges. Ezért a perzisztencia réteg feladata, hogy a referenciát a másik irányba is beállítsa. További problémát okoz, hogy a külsõ kulcs bármelyik entitásban szerepelhet, ezért annak tényleges helyét a forráskódban a perzisztencia réteg számára valahol egyértelmûen meg kell adni.
Az egy-több kapcsolat kezelése nagyon hasonló az egy-egy esethez, hiszen az adatbázisban azzal azonos módon van reprezentálva. Ebben az esetben a perzisztencia réteg feladata egyszerûbb abból a szempontból, hogy a külsõ kulcs elhelyezkedése a kardinalitás ismeretében egyértelmû. Azonban az egyik osztályban egy referencia tömböt kell feltöltenie az adatbázis alapján, ami igen összetett feladat.
Mindenképpen a több-több kapcsolatok kezelése a legkörülményesebb. Ebben az esetben ugyanis a perzisztencia rétegnek egy olyan táblát is használnia kell, melyhez osztály nem tartozik. Mind ezen kapcsolótáblának, mind annak mezõinek nevét ismernie kell. Emellett pedig mindkét osztályban a referenciák tömbjét kell kezelnie.
Mindegyik kapcsolat típusnál külön nehézséget okoz, hogy ha a kapcsolódásokat az alkalmazásban valamelyik végpontja felõl megváltoztatjuk, akkor ezen módosítást a másik oldalról is el kell végeznünk. Ennek a redundanciának a kezelése, és ezáltal annak biztosítása, hogy az adatok minden pillanatba konzisztensek legyenek, szintén a perzisztencia rétegre hárul.
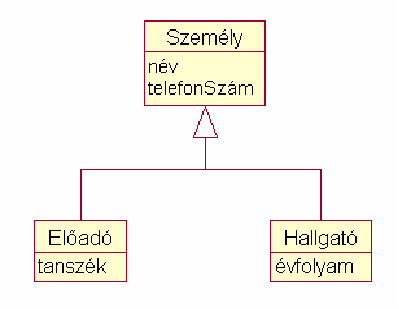
Minden bizonnyal az öröklõdés leképezése jelenti a legnagyobb problémát, hiszen a relációs modellbõl ez a fogalom teljesen hiányzik. A megfeleltetés most nem olyan egyértelmû, mint a korábbi esetekben. Ennek megfelelõen több módszer is létezik. Itt most mindegyiket röviden áttekintjükw11, kitérve azok elõnyeire és hátrányaira. Az egyes módszerekkel példaként az alábbi osztályhierarchiát fogjuk leképezni:
Egy tábla használata a teljes osztály hiearchiára
Ebben az esetben a teljes hierarchiát egyetlen táblában reprezentáljuk, amely az összes elõforduló mezõt tartalmazza. Természetesen a különbözõ osztályokba tartozó objektumokat meg kell különböztetni egymástól, ezért szükség van még egy mezõre, ami az objektum típusát határozza meg.

A példának megfelelõ adatbázis tábla
A módszer legnagyobb elõnye az egyszerûsége. Mind az adatbázis definiálása az osztályok alapján, mind az adatok elérése és kezelése könnyen implementálható a perzisztens rétegben. A sebesség szempontjából hasonlóan elõnyös a módszer, hiszen ebben az esetben különbözõ táblák összekapcsolására – ami rendszerint igen idõigényes – lekérdezéskor nincs szükség, és módosításkor is csak egy táblába kell írni. (A széles rekordok a sebesség szempontjából nem jelentenek hátrányt, hiszen a rekord lapjának megtalálásának idõigénye független ettõl.) Azonban a hátrányok között kell említenünk, hogy az adatbázis mérete fölöslegesen nagy mértékben megnõhet. A legnagyobb probléma azonban az, hogy ha bármelyik osztályon módosítunk, vagy akár egy új osztályt definiálunk, akkor a tábla definícióját módosítani kell, ami – ha az adatbázis már tartalmaz adatokat – a tábla mérete miatt nagyon lassú mûvelet. (Mind az oszlopok, mind a sorok száma nagyon nagy!)
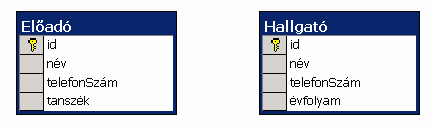
Egy tábla használata minden konkrét osztályra
Ebben az esetben minden konkrét osztályhoz egy olyan adatbázis táblát rendelünk, mely mind a saját mind az örökölt mezõket tartalmazza. Ezzel szemben az absztrakt osztályok semmilyen formában nem jelennek meg az adatbázisban.
A példának megfelelõ adatbázis táblák
Az elõzõ módszerhez hasonlóan egy konkrét osztály minden mezõje egyetlen táblában tálalható, így ez a megoldás is rendelkezik az ebbõl fakadó összes elõnnyel. Azonban ha egy absztrakt osztály mezõit megváltoztatjuk, akkor annak az összes származtatott osztályához tartozó tábláját módosítanunk kell. Emellett pedig egy absztrakt osztályra vonatkozó lekérdezést sem tudunk hatékonyan megvalósítani.
Egy tábla használata minden osztályra
Ez a megoldás minden egyes osztályhoz egy külön táblát rendel, ami tartalmazza az objektum azonosítóját (elsõdleges kulcsát), valamint azokat a mezõket, melyeket az adott osztályban definiáltunk. Az alap- és a származtatott osztályokat a közös azonosítókból felépülõ egy-egy kapcsolat rendeli egymáshoz.

A példának megfelelõ adatbázis táblák
Kétségtelenül ez a legflexibilisebb, és egyúttal legnehezebben megvalósítható megoldás. Ebben az esetben ugyanis egy osztály módosítása egyik másik osztályhoz tartozó adatbázis táblát sem érint, illetve egy új osztály is definiálható anélkül, hogy az alaposztályok tábláját módosítani kellene. Elõnyként kell említenünk azt is, hogy az absztrakt osztályokra is igen hatékonyan futtathatunk lekérdezéseket, melynek köszönhetõen annak leszármazottjait azonos módon tudjuk kezelni. A sebesség tekintetében azonban mindenképp hátrányt jelent, hogy adott típusú objektumok lekérdezéséhez több osztályt kell összekapcsolni. (Ez a lassúság valamelyest ellensúlyozható azáltal, ha az adatbázist fizikai szinten intelligensen építjük fel, azaz az egy hierarchiába tartozó adatbázis táblákat külön fizikai diszkeken helyezzük el.)
Egy perzisztens rétegben természetesen több féle leképezést is implementálhatunk, hogy a különbözõ szempontok szerint a fejlesztõ minden esetben maga dönthessen. Azonban az elsõ két megoldás a harmadikkal szemben funkcionalitásában nem, csak sebesség tekintetében lehet elõnyösebb, ezért referencia implementációnkban csak ezt valósítottuk meg.
Az identitás kezelése
Mind az objektum orientált, mind a relációs szemlélet esetén az objektumainkat egyértelmûen azonosítanunk kell. Az elõbbi esetben a problémával a fejlesztõnek nem kell törõdnie, hiszen a referenciák eleget tesznek ennek a feltételnek. A relációs adatbázis esetén azonban minden entitáshoz magunknak kell az elsõdleges kulcsot definiálnunk.
Az elsõdleges kulcs megvalósításának egyik módja, hogy az entitás mezõinek választjuk ki egy olyan részhalmazát, melyek együttesen egyértelmûen azonosítják az adott példányt. Ennek a megoldásnak több, igen komoly problémája van. Mivel a kulcs valamilyen valódi jelentéssel bír, ezért a késõbbi változtatások alkalmával ezek a mezõk módosulhatnak. Ebben az esetben pedig nem csak az adott táblát kell módosítani, hanem minden olyat is, mely erre külsõ kulcsot tartalmaz. Persze a változás azt is eredményezheti, hogy a módosított mezõk már nem azonosítják egyértelmûen a példányokat, ezért új kulcsot kell definiálnunk. A hatékonyság szempontjából hasonlóan rossz a megoldás, hiszen a bonyolult összetett kulcsok egyrészt nagyobbak, így a külsõ kulcsok miatt nagyobb területet foglalnak el, másrészt a táblák összekapcsolását lelassítják. Végül pedig a perzisztencia réteg megvalósítását fölöslegesen elbonyolítja, ha az objektumok azonosítását minden esetben másképp kell kezelni.
Mindezen problémákat elkerülhetjük azáltal, ha mesterséges kulcsokat definiálunk, azaz minden entitáshoz hozzárendelünk még egy mezõt, melynek egyediségérõl mi magunk gondoskodunk, és ezt használjuk elsõdleges kulcsként.
Azáltal, hogy minden entitásunk kulcsa azonos típusú, lehetõség nyílik arra, hogy objektumainkat szélesebb környezetben is egyértelmûen azonosítjuk. Ennek megfelelõen beszélhetünk osztályon belüli, osztály hierarchián belüli, vagy akár elosztott környezetben megvalósított egyediségrõl.
A táblán belüli egyediség egyszerûen megvalósítható egy egész típusú mezõ és egy számláló segítségével, melynek értékét minden egyes beszúrás után megnöveljük. A legtöbb adatbázis-kezelõ beépítetten támogatja ezt a módszert. A perzisztencia réteg megvalósítása esetén azonban ez az út nem járható. Tegyük fel ugyanis, hogy két objektumunk kölcsönösen referenciát tartalmaz egymásra. Ahhoz, hogy bármelyiket beszúrjuk az adatbázisba, a másik azonosítóját már ismernünk kell, azonban azt csak akkor ismerjük, ha már beszúrtuk. Persze a számlálót az adatbázistól függetlenül is megvalósíthatjuk, de ebben az esetben a kölcsönös kizárásról gondoskodnunk kell. (Például egy tábla mezõjét használva, és mindig elvégezve a megfelelõ lockolást. Ez a megoldás azonban igen lassú.)
Amennyiben két osztály egy azonos alaposztályból öröklõdik, akkor azok objektumait egymástól is meg kell tudnunk különböztetni, hiszen elképzelhetõ, hogy azonos módon használjuk õket. (Egy type cast használatával.) Ez az eset azonban egyszerûen visszavezethetõ az elõzõre, hiszen ha a harmadik típusú leképezést használjuk, akkor ez automatikusan meg is történik.
A legrobosztusabb megoldás azonban az, ha minden egyes objektumhoz egy globálisan egyedi azonosítót rendelünk. Ennek egyik megvalósítása a GUID (Global Unique Identifier). Ez egy 128 bites típus, mely felhasználja az hálózati Ethernet kártya azonosítójának gyárilag biztosított egyediségét, és az aktuális idõpontot. Ezek segítségével megoldható ugyanis, hogy minden egyes azonosító különbözzön a többitõl. A 2128 féle azonosító elég sok ahhoz, hogy akár egy világ méretû elosztott környezetben – mint amilyen az Internet – is meg tudjuk különböztetni az objektumainkat (körülbelül ennyi atom van a Világegyetemen!), ugyanakkor a 128 bit elég kevés ahhoz, hogy a mai processzorok számára ne jelentsen különösebb overhead-et.
A globálisan egyedi azonosító használatával az elosztott környezet kezelése mellett megoldhatjuk kölcsönös kizárás nélkül az azonosítók párhuzamos elõállítását, és mivel értékük az adatbázistól is független, ezért már a beszúrás elõtt is ismerhetjük õket. Ennek megfelelõen a körkörös hivatkozások kezelését is megoldja.
Ennek megfelelõen a referencia implementációban elsõdleges kulcsként GUID típusú mezõket használunk. Mivel a megvalósításhoz a .NET framework-öt és az SQL Server 2000-et választottuk, és a GUID típust mindkettõ támogatja, ezért az implementáció ezen része nem okozott nehézséget.
A lekérdezés
A perzisztencia réteg megvalósításának két módja lehetséges. Az elterjedtebb megoldás az, amikor az objektumokat csak egészükben lehet lekérdezni, azaz az összes mezõjükkel együtt. Ebben az esetben a null értékek kezelésével nincs gond, hiszen az adatbázis és az objektumorientált nyelvben ezek egyaránt léteznek, így megfeleltethetjük õket egymásnak. Ez a megoldás azonban hatékonyság szempontjából nagyon rossz. Ha ugyanis egy objektumban csak egy egész típusú mezõ értékére van szükségünk, akkor is lekérdezzük az adatbázisból az összes mezõt, melyek közt akár nagyon hosszú sztringek vagy bináris adatok is lehetnek. Emellett egy újfajta, az SQL-tõl eltérõ lekérdezõ nyelvre van szükség, így nem használható közvetlenül a relációs adatbázis-kezelõ interfésze, ami nagy mértékben elbonyolítja a perzisztencia réteg megvalósítását. Ennek egy következménye az is, hogy nem használhatunk tárolt eljárásokat, melyek bizonyos esetekben nagyon hatékonyak.
Az általunk elképzelt új, ettõl koncepcionálisan eltérõ megoldás szerint a lekérdezés folyamatát továbbra is teljes egészében a relációs adatbázis-kezelõ végzi. A leképezés csak a lekérdezés után, a kapott eredmény halmaz alapján történik meg. Ennek eredményeként különbözõ típusú objektumok oszlopainak egy halmazát kapjuk. Ebbõl osztály- vagy alias név alapján lekérdezhetjük a megfelelõ oszlopot, majd abból az objektumokat a megfelelõ sorrendben. Természetesen egy oszlopban minden objektum csak egyszer fordulhat elõ. Ez azonban nincs hatással a sorrendre, hiszen ha egy objektum többször fordul elõ az eredményben, akkor mivel mezõinek értéke adott, így egymás után fog többször szerepelni. (A sorrend az egy-több és több-több kapcsolatok esetében is felhasználható!)
Tekintsük példaként az alábbi lekérdezést (SQL Server 2000):
|
SELECT id, name, friends = CASE id WHEN friends1 THEN friends2 ELSE friends1 END FROM Person INNER JOIN Friend ON ( id = friends1 OR id = friends2 ) ORDER BY name |
Tegyük fel, hogy definiáltunk egy osztályt Person néven, melyben különbözõ személyek adatait tartjuk nyilván. Például minden személy nevét (name), és egy tömbben az adott személy barátait (friends). Az adatbázisban tartozzon az osztályhoz egy Person nevû tábla, míg a több-több kapcsolathoz egy Friend nevû kapcsoló tábla. A lekérdezés eredményeként ekkor megkapjuk az összes személyt név szerinti sorrendben (mindegyiket csak egyszer!), és az objektumok friends tömbjében benne lesznek az adott személy barátai szintén név szerinti sorrendben.
Természetesen a megoldás megvalósításánál felmerül egy nehézség, mégpedig annak nyilvántartása, hogy mely mezõk vannak lekérdezve, és melyek nem. Amennyiben erre a célra egy külön adatszerkezetet használnánk, az overhead nagy mértékben megnõne. Ezért választottuk azt a megoldást, hogy ezen mezõk értékét egyszerûen null-ra állítjuk. Ez persze azzal az igen nagy korlátozással jár, hogy nem használhatunk null értékeket az adatbázisban. Mielõtt a probléma súlyosságára kitérnénk, tekintsük meg, hogy mit ír Kalen Delaney2 a null értékek használatáról:
A null értékek használata megnöveli az adatok kezelésének komplexitását, mert az SQL Server egy speciális bittérképet tart nyilván annak tárolására, hogy egy rekord mely mezõi null értékûek éppen. Ha a null értékek engedélyezettek, akkor minden egyes sor elérésekor az SQL szervernek ezt a bittérképet meg kell vizsgálnia. A null értékek használata az alkalmazás bonyolultságát is megnöveli, ami gyakran hibákhoz vezet. Adatbázis tervezõként meg kell értened a null értékek megkülönböztetésének, és a három értékû logikák használatának problémáját az oszlopfüggvényekben, táblák összekapcsolásakor és érték szerinti kereséskor. Azt ajánlom, ha ez lehetséges, akkor minden mezõt definiálj a NOT NULL módosítóval, és használj alapértelmezett értékeket a hiányzó vagy ismeretlen értékek kezelésére.
Bármely más adatbázis-kezelõ kézikönyvét olvasva hasonló tanácsokat találnánk. Ezért a megoldás ezen hátránya csak egy olyan megszorítás, amit amúgy is célszerû betartanunk.
Fontos megjegyeznünk, hogy a null értékek használata nélkül is lehetnek olyan kapcsolatok, ahol egy objektumhoz nem rendelünk másikat. Ebben az esetben egy adott speciális érvénytelen azonosítót kell használnunk az adatbázisban.
A megoldás ezen megszorításért cserébe rendelkezik mindazokkal az elõnyökkel, melyek az elõzõ módszer esetében hátrányként jelentkeztek. Egyrészt a lekérdezések hatékonyabbak, mert csak azokat az információkat kapjuk meg, melyekre valóban szükségünk van. Másrészt perzisztencia réteg megvalósítása lényegesen egyszerûbb, hiszen a lekérdezés folyamatába nem kell beleavatkoznia. Végül pedig kihasználhatjuk az adott adatbázis-kezelõ SQL nyelvi kiterjesztését az abban rejlõ lehetõségekkel együtt.
Tárolt eljárások
A tárolt eljárások lehetõsége a modern adatbázis-kezelõk egyik legerõteljesebb szolgáltatása. Ez lényegében egy az SQL nyelv valamilyen kiterjesztésén keresztül definiálható függvény, ami teljes egészében az adatbázis szerveren fut le. Ennek köszönhetõen egyes mûveletek (melyek a gyakorlatban tipikusan lekérdezések) sebessége a sokszorosára növelhetõ, mert a szûk keresztmetszetet jelentõ hálózati forgalom lecsökken. Emellett azonban hátrányként jelentkezik, hogy a „forráskód” egy része elkülönül, így az kevésbé áttekinthetõvé válik, illetve az adatbázis változtatása ezen eljárások módosítása miatt nehézkesebbé válik.
Az imént említett lekérdezési módszer egyik legnagyobb elõnye, hogy lekérdezéskor használhatunk tárolt eljárásokat is.
Tekintsük az alábbi példát (Transtact-SQL):
|
CREATE PROC GetFriends @root VARCHAR(50) AS BEGIN CREATE TABLE #Person( id UNIQUEIDENTIFIER, name VARCHAR(50) ) INSERT INTO #Person SELECT * FROM Person WHERE name = @root WHILE ( @@ROWCOUNT > 0 ) INSERT INTO #Person SELECT id, name FROM Person INNER JOIN Friend ON ( id = friends1 OR id = friends2 ) WHERE CASE id WHEN friends1 THEN friends2 ELSE friends1 END IN ( SELECT id FROM #Person ) AND id NOT IN ( SELECT id FROM #Person ) SELECT id, name, friends = CASE id WHEN friends1 THEN friends2 ELSE friends1 END FROM #Person INNER JOIN Friend ON ( id = friends1 OR id = friends2 ) ORDER BY name END |
Ez a rövid eljárás egy az elõzõ példához hasonló eredményt ad, de itt csak azokat a személyeket kapjuk meg, melyek a paraméterben kapott személlyel közvetlen vagy közvetett baráti kapcsolatban állnak. Ennek megfelelõen az eljárás egyfajta tranzitív lezárást hajt végre, melyhez egy ideiglenes, csak a memóriában létezõ táblát hoz létre és használ fel. Amennyiben mindezt a kliens oldalon végeznénk el, akkor mind a hálózati forgalom, mind a kevésbé hatékony adat reprezentáció miatt a lekérdezés lényegesen lassabb lenne.
Beszúrás, módosítás és törlés
Ezen három mûvelet megvalósítása igen egyszerû. Ha minden perzisztens osztályt egy közös õsosztálytól származtatunk, akkor ebben kell implementálnunk a három megfelelõ metódust. A szükséges információk mind a rendelkezésünkre állnak, hiszen reflection segítségével felderíthetjük a mezõk neveit, lekérdezhetjük azok értékeit, és tudjuk, hogy amelynek értéke null, az nem lett lekérdezve, így nem is kell módosítani.
A hagyományos objektum esetében megszoktuk, hogy ha már nincs rájuk szükség, akkor a szemétgyûjtõ azt automatikusan eltávolítja. Ennek megfelelõen a perzisztencia réteg feladata megoldani azt, hogy ha egy perzisztens objektum nem lett beszúrva az adatbázisba, vagy a rajta végzett módosítások nem jelentek meg ott is, akkor ezeket a mûveleteket az objektum megszûnésekor automatikusan hajtsa végre.
Ennek kapcsán azonban felmerül egy igen nehezen átlátható probléma. A szemétgyûjtõ ugyanis elméletileg az objektumokat teljesen véletlen sorrendben szünteti meg, így azok finalize metódusai is egymástól függetlenül hívódnak meg. Egy beszúrás vagy módosítás mûvelet esetén pedig szükségünk lehet az adott objektummal kapcsolatban álló más objektumok azonosítójára, mely lehet, hogy már korábban megszûnt. Szerencsére a .NET framework esetében a szemétgyûjtõ algoritmus olyan, hogy ez a probléma megoldható. Mivel ugyanis elképzelhetõ, hogy a finalize metódus hatására az objektum „újjászületik”, azaz újból elérhetõvé válik, ezért a szemétgyûjtõ azokat az objektumokat, melyekben ez a függvény implementálva van csak a következõ szemétgyûjtés alkalmával szünteti meg. Ennek megfelelõen az egy idõben megszûnõ perzisztens objektumok finalize hívásaikor még egytõl-egyig léteznek.
Összegzés
Véleményem szerint az objektum-relációs leképezés egy a közeljövõben széles körben elterjedt módszerré válhat. Ezt igazolja az is, hogy a SUN is meg fog jelentetni hamarosan egy ilyen jellegû kiegészítést a Java-hoz, JDO (Java Data Objects) néven. Azonban úgy gondolom hogy az általunk választott, a hagyományostól kissé eltérõ koncepciónak meg vannak a maga elõnyei, melyek miatt mindenképp helyet érdemel a többi megoldás mellett.
Noha még különbözõ problémák állnak elõttünk, a fejlesztésünk eredményei bíztatóak, így egy ilyen jellegû perzisztencia réteg szinte teljesen átlátszó és hatékony megvalósítása kivitelezhetõnek tûnik.
Irodalomjegyzék
[1] Kalen Delaney: Inside SQL Server 2000 (2001)
[w1] Scott W. Ambler: Mapping Objects To Relational Databases (1998-2000)
/ http://www.AmbySoft.com/mappingObjects.pdf /
1w1 Scott W. Ambler: Mapping Objects To Relational Databases (1998-2000)
2 Kalen Delaney: Inside SQL Server 2000 (2001)