Ontológia-alapú Tudástárház Rendszerek
Dezsényi Csaba, Varga Péter, Mészáros Tamás, Strausz György, Dobrowiecki
Tadeusz
Méréstechnika és Információs Rendszerek Tanszék,
Budapesti Műszaki és Gazdaságtudományi Egyetem (BMGE),
Budapest, 1117, Magyar tudósok körútja 2.
{dezsenyi, pvarga, meszaros, strausz,
dobrowiecki}@mit.bme.hu
1. Bevezetés
A bemutatásra kerülő információ elemzési és kinyerési technikák fejlesztése az “Információ és Tudás Tárház” (angol rövidítés: IKF) projekt keretében zajlik. A projekt fő célja egy olyan újfajta Intelligens Tudás Tárház Rendszer elemzése, specifikálása és kivitelezése, amely lehetővé tesz fejlett Tudás Menedzsmentet és Üzleti Intelligenciát különböző meghatározott alkalmazási területeken. Az IKF alkalmazások a piaci szektor széles körét lefedik: pénzügy (bankok és biztosítótársaságok), egészségügy, banki szabályozások, oktatás és képzés, jogi információk, ipar. Ezeknek a területeknek kulcsszerepük lesz az egyes IKF keretrendszerek technológiai eszközeinek hangolásában [1].
A magyar konzorcium feladata egy tudásalapú
információ-visszakereső rendszer kifejlesztése pénzügyi cégek és bankok
részére. A rendszer fő tevékenysége az információ téma-specifikus,
különböző forrásokból (internet, intranet erőforrások, adattárházak,
stb.) történő beszerzése és elemzése, és az információ strukturált
szolgáltatása a felhasználók felé. Ez különböző döntéstámogató megoldások
alapját képezheti a magyar banki vagy egyéb üzleti szektorban.
A következőkben az IKF-H prototípus rendszer
információ beszerzés oldali folyamatait összegezzük. A rendszer elsősorban
magyar nyelvű dokumentumokat gyűjt be és elemez az internetről,
amely új problémákat vet fel a hagyományos információ kinyerési technológiák
alkalmazásánál.
1.1. A probléma általános modellje
Az IKF rendszer absztrakt környezet modellje három
fő részre osztható (1. ábra): A Cél Környezet (pl. az aktuális cégek,
ügyfelek, stb.), Az Információ Forrás Környezet (pl. internet, adattárház,
stb.) és az Információ Felhasználási Környezet (pl. banki menedzsment,
személyzet, stb.).
A Cél Környezet (Target Environment) a témához
kapcsolódó tudás fizikai forrása, a valós világ objektumait tartalmazza, azok
közötti relációkat, összefüggéseket, stb. Ez mind a két másik környezetet
meghatározza, illetve befolyásolja. A rendszerhez szükséges tudásbázis,
tudásmodell a Cél Környezet elemzésével, modellezésével jöhet létre.
Az Információ Forrás Környezetben (Information
Cumulating Environment) találhatóak azok a dokumentumok, szöveges anyagok,
melyek egyrészt tükrözik a Cél Környezet modelljét, másrészt tartalmazzák a
szükséges információt a rendszer számára és elérhetőek digitális úton.
Az Információ Felhasználási Környezetben
(Information Utilization Environment) helyezkednek el azok a felhasználók, akik
bizonyos tudást akarnak beszerezni a Cél Környezetről, hogy céljaikat
elérjék. Ezt az Információ Forrás Környezetből tudják kinyerni a rendszer
segítségével.
Egy korábbi
publikációban bemutattuk a problémakör általános modelljét, illetve egy
ajánlott magas-szintű IKF architektúrát [2,3]. Az architektúra három
fő komponensből áll: Dokumentum Beszerző és Elemző,
Információ Menedzser, illetve Információ Lekérdező modulok. A
következőkben a Dokumentum Beszerző és Elemző modult mutatjuk be
részletesen. Ez a modul gondoskodik a dokumentumok forráskörnyezetből
történő beszerzéséről (tipikusan a világhálóról), illetve az adott
alkalmazás igényeinek megfelelően, a dokumentumok elemzéséről.
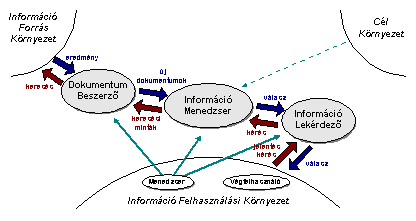
1. ábra: Az IKF Információs folyam
2. A tárgyterületi tudás megjelenése
Az IKF projekt célja mind a funkcionalitásról
szóló általános jellegű, mind a tárgyterületről szóló specifikus
jellegű tudás beépítése az IKF Alkalmazásba. Ezt a célt tölti be a
Tárgyterület Modellező alrendszer.
Nyilván a tárgyterületi tudás és a funkcionalitás
általános tudása csak tárgyában válik el, tárolásának technológiája
azonos. Erre a technológiai feladatra
az IKF projekt – a lehetőségek alapos felmérése után – a mesterséges
intelligencia logikai-tudásreprezentációs irányzatának egy megoldása, a tudást
tároló ontológiák alkalmazása mellett kötelezte el magát.
2.1. Tudás modellezése ontológiák segítségével
Az ontológia görög kifejezés, és már régóta ismert
a filozófiában. Ez a tény jelzi, hogy az ontológia, mint tudásreprezentációs
informatikai eszköz erős interdiszciplináris gyökerekkel, megalapozott
háttérelmélettel rendelkezik, ugyanakkor – főként a kilencvenes évek
derekától kezdve – a mesterséges intelligencia kutatásának bevett fogalma és
gyakorlatának produktív eszköze lett.
Az ontológia feladata a működő
rendszerekben – leegyszerűsítésekkel – az, hogy karakterizálja a tudást
tartalmazó tudásbázis lehetséges feltöltöttségeinek olyan megszorítását, amely
biztosítja, hogy a tudásbázis minden lehetséges tartalma összhangban legyen a
(valós világbeli) fogalmi sémával (mindennek elméleti kifejtését ld. pl. [7]).
Az ontológiák választását a tudásreprezentáció
szerepére az is motiválta, hogy az IKF projekt megcélozta gazdasági
tárgyterület és az azt leíró gazdasági nyelv egy elméleti diszciplína, a
közgazdaságtudomány hatására formálódik, tehát – várhatóan és részben
beigazoltan – logikailag feltárhatóak fogalmi viszonyai. Ugyanakkor az
informatikai ontológia-kutatás jelenleg az elosztott előkészített
tudásrészeken operáló ágensek interoperabilitásának (szemantikus web)
megteremtésére törekszik. Ez hosszú távon lehetővé teszi az IKF Alkalmazás
és a szemantikus web rendszerei közti könnyebb átjárhatóságot, a jelenben
azonban megoldandó feladatot jelent, mivel az IKF Alkalmazás
forráskörnyezetének dokumentumai jelentős részben gép feldolgozásra
előkészítetlenek (lévén csak embereknek íródtak), tehát az ontológiákkal
kapcsolatos eddigi eredmények közvetlenül nem vehetők át. Mindez az IKF
projekt saját ontológia-elképzelésének (szintaxis és szemantika) kialakítását
tette szükségessé.
2.2. Az IKF Alkalmazás saját ontológia-elképzelése
Az egyes ontológiák vázát taxonomikus struktúrák
összessége adja. Egy taxonómia lényegileg fogalmak tartalmazási reláció (is-A)
szerinti irányított fagráfja. A modellezett tudás szempontjából a tartalmazás
reláció egy fogalmat (az ún. nemfogalmat) több fogalomra (ún. fajfogalmakra)
bont. A gráf minden csomópontjában (a levelekben is) fogalom áll, ugyanakkor
mindegyik csomópontnak lehet példánya. Az ontológiában előre rögzített
számú és szemantikája (ez rögzített felső fogalmakat jelent) fagráf lehet.
Az egyes fagráfokat kategóriáknak (pl. szubsztancia, mennyiség, minőség,
viszony kategóriái stb.) nevezzük és interdiszciplináris megfontolások alapján
határoztuk meg. (A jelenlegi tárgyterület modellező alrendszer tíz ilyen
kategóriát ismer). A kategóriák a lentebb ismertetendő funkcionalitásoban
kapják meg jelentőségüket, de egyben irányadó segédeszközként is
szolgálnak az ontológiák építésekor.
A fogalmak csupasz tartalmazási relációi azonban
nem elegendőek. Egymás közti viszonyaikat az interkategoriális kényszerek
modellezik. Az interkategoriális kényszer (akár különböző kategóriájú)
fogalmakat köt össze: azt modellezi, hogy az egyik fogalom milyen (akár
komplex) fogalmat von maga után.
Az IKF projekt során kialakult
ontológia-elképzelés ugyan logikai tudásreprezentációs eszközt használ, de a
logikai precizitást csak a forráskörnyezet (strukturálatlan szabadszöveges
dokumentumok) megszabta mértékben alkalmazza. A logika szükségessége a fogalmak
közti kizárási viszonyok és a komplex interkategoriális kényszerek miatt
jelenik meg (amik következtében nem triviális feladat, pl. egy összetett
fogalom tartalmazási reláció szerinti vizsgálata).
Az IKF Alkalmazás ezen alrendszerét tényleges
használatbavétele előtt tehát még paraméterezni kell, azaz fel kell
tölteni a feladat- és intézmény-specifikus tárgyterületi tudással. Ugyanakkor
az IKF projekt célja ezen paraméterezés megkönnyítése mind a tárgyterületi
modellépítő komponenssel, mind a tudástárban már előzetesen
meglévő részlegesen elégendő tudással.
3. Információ beszerzés
Egy általános probléma amivel szembe kell néznünk
a Forrás Környezetben tárolt, Cél Környezetre releváns információval
kapcsolatos. A felhasználóknak általában nincsen kellő ismeretük arra
nézve, hogy a keresendő adatok, tudásanyag hogyan van tárolva a
forrásokban. Az IKF rendszer feladata, hogy ezeket a modelleket felfedje és
beszerezze a szükséges információkat a felhasználók számára.
Annak ellenére, hogy manapság igen sok információforrás
szolgáltat hasznos adatokat a különböző tárgyú alkalmazások számára, az
emberi értékelésre még mindíg szükség van a releváns információ
kiválasztásához, hiszen a legtöbb forrás tartlama strukturálatlan formában áll
rendelkezésre. Az egyik fő vezérvonala az IKF megközelítésnek az, hogy
különböző, tárgyterület specifikus tudás-modell felhasználásával kell
támogatni az információ beszerző folyamatokat. A következőkben az IKF
prototípus rendszer információ beszerző moduljának strukturáját fogjuk
megvizsgálni, majd rátérünk az ontológia alkalmazására.
3.1. Az IKF Információ Beszerző
rendszer
Az Információ Beszerző alrendszer feladata,
hogy miközben automatikusan bejárja az információ forrásokat, beszerezze a
megfelelő dokumentumokat és egy előelemzés segítségével
előkészítse a további, mélyebb információ kinyeréshez. Maga a modul
ágensként viselkedik [5]: a céljait más IKF moduloktól kapja meg (mint
dokumentum forrás URL-ek és keresési minták), a felkonfigurált célokat pedig a
megfelelő dokumentumok felkutatásával,
beszerzésével és elemzéséval éri el [2,4]. A rendszer felépítése és
működési mechanizmusa az alábbi ábrán látható (2. ábra).
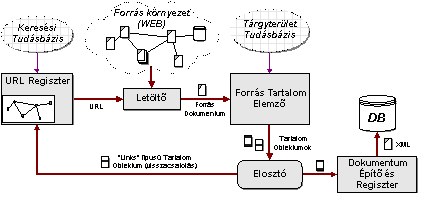
2. ábra: A dokumentum beszerző
alrendszer architektúrája
A rendszer a következőképpen működik: az
URL regiszter a forráskörnyezetről épít egy belső, gráf-alapú modellt
működés közben. Ezzel megvalósulhat, hogy a webrobot ne csak a közvetlen
környezetét érzékelje lokálisan, hanem globális képe legyen a már megismert
forráskörnyezetről. A belső modell segítségével hatékony gráf-alapú
algoritmusok implementálhatóak, amelyek az URL-kiválasztási mechanizmust
vezérlik. A Downloader modul feladata, hogy a regiszter által kiválasztott
címen lévő dokumentumot letöltse a forráskörnyezetről (az
internetről) és előállítsa az ún. IKF Forrás Dokumentumot, ami egy
XML fomrátumú belső reprezentációja az eredeti forrásdokumentumnak.
A következő lépés a forrásdokumentumok
elemzése. Ezt a Forrás Tartalom
Elemző egység végzi, amely azért felelős, hogy a bejövő
dokumentumok bizonyos strukturális és egyéb fontos jellemzőit felismerje.
Ennek segítségével előállítja az ún. Tartalom Objektumokat, amelyek a
különböző típusú releváns információkat tartalmazzák, amelyeket az eredeti
dokumentumból nyer ki az elemző. A Tartalom Objektumok technikailag XML
dokumentumok, amelyek a felkonfigurált alkalmazástól függően tartalmazzák
strukturált formában a kinyert információ-elemeket. A felkonfigurálástól
függöen lehet az objekumoknak típusuk, például egy általános és egyszerű
típus lehet olyan, amely egy dokumentumból kinyert linkeket tartalmazza.
A Tartalom Objektumokban az XML címkék tipikusan
strukturálatlan szövegrészleteket fognak közre, azonban ezek a töredék szövegek
tartalmazzák az alkalmazás számára lényeges információt, amelyet a további IKF
elemzők kinyernek. A Forrás Tartalom Elemző szöveges statisztikai
elemzést is végrehajt a Tartalom Objektumokon, amivel pontosabb képet kap a
rendszer az adott objektumról. Az elemző a létrejövő indexet és
statisztikai relevancia információt az objektumhoz csatolja.
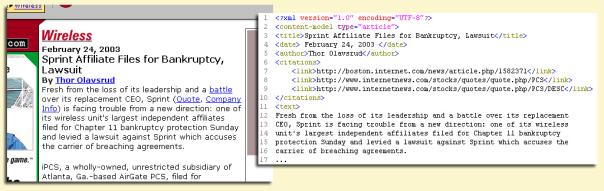
3. ábra: Példa a forrásdokumentum
elemzésre
Az fenti ábrán (3. ábra) egy példát láthatunk
arra, hogy a rendszer milyen formában vágja ki a szükséges információt egy
portál cikkeiből. A baloldalon található maga a portál cikk. A cikket
magábafoglaló oldal számos zavaró elemet is tartalmaz (hírek, menük, linkek,
stb.), amelyek nem kívánatosak az alkalmazás számára. A jobboldalon pedig az
„article” típusú tartalom objektum látható, amely az elemzés során létrejött.
Ebben az egyszerű példában a cikk címe, szerzője, dátuma, szöveges
tartalma, illetve a cikkben szereplő hivatkozások lettek kigyűjtve.
4. Az ontológiákra épülő funkcionalitások
Mi a haszna a tudás modellezésének az IKF projekt
céljainak szempontjából? Erre a kérdésre az ontológiára épülő funkcionalitások
adják meg a választ. Ezeket a funkcionalitásokat az IKF projekt során
folyamatosan fejlesztjük.
4.1. A keresőkérdésekkel kapcsolatos funkcionalitások
A keresőkérdéssel kapcsolatos
funkcionalitásokat már sikeresen kidolgoztuk és – prototípus szinten –
implementáltuk is. Az implementáció két funkcionalitást valósít meg. Az
első funkcionalitás arra az igényre válaszol, hogy a természetes nyelv és
a Dokumentumtár indexelt dokumentumainak indexnyelve közt komoly különbségek
lehetnek (poliszémia, szinonímia stb. miatt). A másik funkcionalitás pedig
abból indul ki, hogy egy indexalapú keresés sikerességét sokban javítja egy
gondosan kiválasztott, több-összetevős keresőszó-lista.
A két funkcionalitás együttese tehát a természetes
nyelven megfogalmazott keresőkérdést úgy alakítja át a Dokumentumtár
indexnyelvén megfogalmazott keresőkérdéssé, hogy nem csak a
keresőkérdés szavainak indexnyelvi megfelelőjét tartalmazza, hanem a
háttértudás által vonatkozónak tartott indexnyelvi szavakat is. Ez a
kibővítési eljárás bővítési operátorok használatával történik.
Először meg kell keresni a természetes nyelvi szavak által jelölt fogalmak
ontológiabeli megfelelőjét, mert a bővítési operátorok az ontológián
értelmezettek. Minden bővítési operátor egy adott fogalomból kiindulva
három fogalomlistát eredményez: a tartalmazó, az azonos és a tartalmazott
fogalmak listáját. Ehhez a három fogalomlistához három különböző
súlytényező is tartozik (az eddigi tapasztalatok alapján a legkisebb
súllyal a tartalmazott fogalmakat kell figyelembe venni, míg az azonos fogalmak
súlytényezője természetesen egységnyi). A konkrét bővítési operátorok
ennek a sémának a kitöltésével származtathatók: a kiinduló fogalom lehet a
keresőkérdés fogalma (a tapasztalat alapján a bővítési operációnál vagy-szemantikát
kell alkalmazni), annak negáltja és az interkategoriális kényszerei által
implikált fogalmak. A bővítési operátorok konkretizálása során ismét
megjelenik egy súlytényező (pl. a negált esetben negatív egységnyi, az
interkategoriális fogalmaknál egy diszkontáló jellegű tényező), amely
a másik súlytényezővel összeszorzódik.
Ezután a fogalomból az indexnyelvi szót kell
származtatni. Mivel egy fogalomhoz több indexszó is tartozhat, amelyek közül
egyesek kevésbé jellemzőek, ezért itt ismét fellép egy súlytényező.
Az összevont funkcionalitás kimenetén ennek a konverziónak az eredménye jelenik
meg.
A keresőkérdéssel kapcsolatos két, összevont
funkcionalitás fő hátránya az IKF projekt jelenlegi szakaszában, hogy csak
az ontológiában megtalálható fogalmakat közvetlenül megnevező szavakat
tudja hasznosítani. A továbblépéshez a példánykezelés bevezetése szükséges. Ez
a tervbe vett következő funkcionalitás melléktermékeként lenne lehetséges.
4.2. Az információkinyerő funkcionalitás
Az IKF projekt jelenlegi szakaszában intenzív
munka folyik egy újabb funkcionalitás kidolgozására. A Morphologic Kft.
morfoszintaktikai elemzőjére támaszkodva készült a projekt keretében egy
mondatelemző, amelynek kimenetét az ontológiához kell kapcsolni. Ez – az
eddigi kísérletek alapján – várhatóan lehetővé tesz szövegmegértési
jellegű, mindazonáltal nem teljes információkinyerést a természetes
szövegekből. A melléktermékként létrejövő fogalom-példány
megfeleltetésekből pedig a fent leírt keresőkérdés-kiegészítő
funkcionalitás is profitálhat.
4.3. Implementáció és példafuttatás
Mint említettük, az IKF projekt keretében a
keresőkérdés-kiegészítő funkcionalitáshoz egy prototípus szintű
implementáció is készült. Az implementáció egy többszálú Java komponens, amely
TCP/IP socketeken keresztül kommunikál XML formátumban. Ontológiai és
konfigurációs adatait szintén XML formátumban tárolja.
Az implementációhoz fel kellett használni egy
leíró-logikai (description logic) következtetőgépet, amely a
funkcionalitás igényelte logikai apparátust biztosítani tudta. Ehhez a Ian
Horrocks készítette Fast Classification of Term (FaCT) rendszert használtuk fel
(ld. [6,8]). Ez egy LISP modul, amellyel CORBA interfészen át lehet
kommunikálni. A leíró-logikai következtetőgép kiválasztása csupán a prototípus
implementációjának szakaszára szólt, az IKF projekt további szakaszában
elképzelhető egy előnyösebb tulajdonságú másik következtetőgép
választása. Ezt a flexibilitást az teszi lehetővé, hogy a
következtetőgéppel való kommunikációhoz szükséges fordítást csak a
lehető legalsó rétegben végezzük el.
Tekintettel a magyar nyelv agglutináló jellegére,
a komponens bemeneté érkező szavakat az említett morfoszintaktikai
elemző a további konverziók előtt tövesíti.
 A prototípus szintű implementáció
bizonyította az elképzelést működőképességét, és rámutatott a
továbbfejlesztést igénylő pontokra. Felmerült azonban az igény a
funkcionalitás eredményességét kvantitatív és kvalitatív módon jellemző
teszt iránt. Ezt kielégítendő egy olyan teszt készült, amely a funkcionalitásnak
konkrét keresési szituáció eredményére gyakorolt hatást vizsgálta. A keresés
célja a számítógépes biztonságtechnikából ismert ún. exploitokkal kapcsolatos
dokumentumok megtalálása volt (a szó poliszémiája és a különböző
kontextusok miatt a klasszikus index-alapú keresési módszer nagyon rosszul
teljesítenek, pl. egy népszerű keresőportál első tíz találatából
négy irreleváns). Olyan dokumentumokból
indultunk ki, amelyek tartalmazzák az „exploit” szót. Az IKF Alkalmazás
forrásdokumentum-beszerző rendszere kollekció 101 ilyen dokumentum
kollekcióját hozta létre (összesen 1.2 MB méretben), amelyek között – a
kereséséi szituáció természetéből fakadóan – tematikailag irreleváns
dokumentumok is voltak. A keresést (azaz a relevánsnak ítélt dokumentumok kiválogatását
és a találatok rangsorolását) egy a vektormodellt használó indexelő
program végezte, amely szintén az IKF projket részeként készült. (Mint
ismeretes ebben a keresési modellben a dokumentum illeszkedését a
keresőkérdés és a dokumentum indexszavak terében értelmezett vektorai
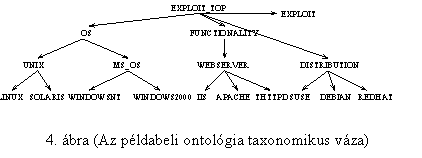
által bezárt szög koszinuszával lehet mérni.) tesztcélú ontológia az operációs
rendszerek, az exploit és néhány hasonló fogalom kapcsolatát modellezi
(természetesen ez elkészítésekor nem törekedhettünk sem a teljességre, sem a tárgyterület
precíz modellezésére). A mini-ontológia taxonomikus váza a 4. ábrán látható (a
megjelenítetteken kívül még három interkategoriális reláció is szerepelt az
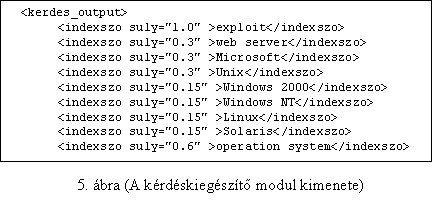
ontológiában). A korábbiakban leírt modul a keresési kérdést az 5. ábrán
látható módon bővítette ki.
A prototípus szintű implementáció
bizonyította az elképzelést működőképességét, és rámutatott a
továbbfejlesztést igénylő pontokra. Felmerült azonban az igény a
funkcionalitás eredményességét kvantitatív és kvalitatív módon jellemző
teszt iránt. Ezt kielégítendő egy olyan teszt készült, amely a funkcionalitásnak
konkrét keresési szituáció eredményére gyakorolt hatást vizsgálta. A keresés
célja a számítógépes biztonságtechnikából ismert ún. exploitokkal kapcsolatos
dokumentumok megtalálása volt (a szó poliszémiája és a különböző
kontextusok miatt a klasszikus index-alapú keresési módszer nagyon rosszul
teljesítenek, pl. egy népszerű keresőportál első tíz találatából
négy irreleváns). Olyan dokumentumokból
indultunk ki, amelyek tartalmazzák az „exploit” szót. Az IKF Alkalmazás
forrásdokumentum-beszerző rendszere kollekció 101 ilyen dokumentum
kollekcióját hozta létre (összesen 1.2 MB méretben), amelyek között – a
kereséséi szituáció természetéből fakadóan – tematikailag irreleváns
dokumentumok is voltak. A keresést (azaz a relevánsnak ítélt dokumentumok kiválogatását
és a találatok rangsorolását) egy a vektormodellt használó indexelő
program végezte, amely szintén az IKF projket részeként készült. (Mint
ismeretes ebben a keresési modellben a dokumentum illeszkedését a
keresőkérdés és a dokumentum indexszavak terében értelmezett vektorai
által bezárt szög koszinuszával lehet mérni.) tesztcélú ontológia az operációs
rendszerek, az exploit és néhány hasonló fogalom kapcsolatát modellezi
(természetesen ez elkészítésekor nem törekedhettünk sem a teljességre, sem a tárgyterület
precíz modellezésére). A mini-ontológia taxonomikus váza a 4. ábrán látható (a
megjelenítetteken kívül még három interkategoriális reláció is szerepelt az
ontológiában). A korábbiakban leírt modul a keresési kérdést az 5. ábrán
látható módon bővítette ki.
A teszt eredményeinek kvantitatív
értékelése a 6. ábrán látható, amely az egyes találati pozíciókban álló
dokumentumokra számított numerikus relevancia-becslést tartalmazza (a
koszinuszos vektormodellt használva). Mint látható, a kiegészített keresés nem
csak magasabb relevancia-értékeket szolgáltat (ez még önmagában nem lenne
jelentős, mert a felhasználó nem a relevancia-becsléssel, hanem a találati
pozícióval találkozik), de jobban ki is emeli az eredményeket, ami
relevancia-küszöbérték alkalmazása esetén kevesebb, de várhatóan relevánsabb
eredményhez vezet. A kvalitatív értékéléshez az egyes találati pozíciókban
szereplő dokumentumokat manuálisan a releváns–szemi-releváns–irreleváns
kategóriákban soroltuk. A keresések eredményeinek ilyen értékelése a 7. ábrán
látható.
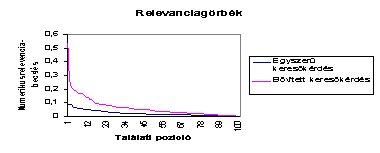
6. ábra (A teszt eredményeinek kvantatív
értékelése)

7. Ábra (Az eredmények kvalitatív
értékelése)
A második keresés nyilvánvaló fölényéből
kiemelhető, hogy sikerült az első találatot is relevánssá tenni, ami
különös fontosságú, ha a keresés eredményét gépi utófeldolgozásra szánjuk.
Összefoglalva megállapítható, hogy a keresési
kérdés kibővítésének módszere megfelelő tárgyterület-specifikus
ontológia feltételezésével jelentős javulást hozhat mind a keresés relevanciájában,
mind a keresés pontosságában. Fontos leszögezni, hogy ez a vizsgálat a tisztán
keresőkérdés-bővítő funkcionalitásra koncentrált, nem
foglalkozott a természetes nyelv és az indexnyelv közti fordításból származó
előnyökkel. Mindez bizonyítja az eddigi eredmények hasznosíthatóságát.
Természetesen a továbbfejlesztés említett igénye mindezek ellenére fennáll,
amint jelenleg is intenzív munka folyik ezeken a területeken az IKF projektben.
5. Összegzés
Bemutattuk, hogy az IKF
projekt szemlélete tükrében hogyan épül fel egy általános információ és tudás
tárház rendszer dokumentum beszerző alrendszere. Kulcsfontosságú feladat
az ilyen rendszer hatékony alkalmazhatósága szempontjából egy megfelelő
tárgyterületi ontológia megalkotása és implementálása, amely alapját képezi az
alkalmazható tudás-kinyerő módszereknek. Praktikus és teoretikus
megfontolásokból is előnyös olyan ontológia szerkesztése, amely a
különböző tárgyterületi fogalmakat olyan struktúrába próbálja szervezni,
mint ahogyan az az emberek gondolati világában jelenik meg.
A kifeljesztett
prototípus rendszer autonóm módon kutat fel és szerez be dokumentumokat
különböző információs forrásokból (pl. webes erőforrások, itt magyar
elektronikus pénzügyi publikációk). A bemutatott ontológiára alapozott
keresőkkérés kiterjesztő funkcionalitást meg lett tervezve és
implementálva lett.
Letöltés után a rendszer
a felkonfigurált forrás modellek alapján a bejövő dokumentumot elemzi és a
kinyerhető információ-elemeket megfelelő XML dokumentumokba (tartalom
objektumokba) transzformálja. Ezen kívül különböző statisztikai szöveges
elemzéseket is végez az objektumokon. Ez a művelet a magyar nyelv
specialitása következtében néhány nyelvészeti elemzést is magába foglal.
A prototípus rendszer
fejlesztése továbbra is folyik és még sok munka szükséges ahhoz, hogy egy a
valós élet alkalmazásai között is helytálló eszköz szülessen. Azonban már az
eddigi munka is rengeteg tapasztalatot adott egy ilyen rendszer
lehetőségeivel és korlátaival, működésével és teljesítő képességével
kapcsolatosan.
A prototípus első
változatával történt tesztek tapasztalatai alapján látható, hogy a rendszer
képessége alapvetően függ a beépített ontológia fejlettségétõl illetve,
hogy a nyelvi eszközök új nyelvtanokkal történő bõvítése és az egyre jobb
nyelvi elemzés után is fennmaradó bizonytalanságok heurisztikus kezelése a
továbbfejlesztés legfontosabb elemei kell hogy legyenek.
6. Hivatkozások
[1] EUREKA PROJECT “IKF - Information and Knowledge Fusion”, Institute of Cognitive Sciences and Technology, Laboratory for Applied Ontology, March 2000.
[2] “The IKF architecture”, IKF project report, Budapest University of Technics and Economics, Department of Measurement and Information Systems, August, 2002.
[3] T. Mészáros, Zs. Barczikay, F. Bodon, T. Dobrowiecki, Gy. Strausz, “Building an Information and
Knowledge Fusion System”, IEA/AIE-2001 The Fourteenth International Conference on Industrial &
Engineering Applications of Artificial Intelligence & Expert Systems, June 4-7, 2001, Budapest, Hungary
[5] J. M. Broadshaw, “Software Agents”, The MIT Press, 1997
[6] S. Bechhofer, I. Horrocks, P. F. Patel-Schneider, and S. Tessaris, “A proposal for a description logic interface” In P. Lambrix, A. Borgida, M. Lenzerini, R. Möller, and P. Patel-Schneider, editors, Proceedings of the International Workshop on Description Logics (DL'99), pp. 33-36, 1999.
[7] Guarino, N., “Formal Ontology in Information Systems” In N. Guarino (ed.) Formal Ontology in Information Systems. Proceedings of FOIS'98, Trento, Italy, 6-8 June 1998. IOS Press, Amsterdam
[8] I. Horrocks, “Using an expressive description logic: FaCT or fiction?” In A. G. Cohn, L. Schubert, and S. C. Shapiro, editors, Principles of Knowledge Representation and Reasoning: Proceedings of the Sixth International Conference (KR'98), pp. 636-647. Morgan Kaufmann Publishers, San Francisco, California, June 1998.