Tartalomalapú
képkinyerés képarchívumokból – van ilyen?
Veréb
Krisztián
Debreceni Egyetem
Matematikai és Informatikai
Intézet
Információ Technológia
Tanszék
sparrow@math.klte.hu
Kivonat
A multimédia térhódításával a képek adatbázisbeli tárolására és visszakereshetőségére is megjelent az igény. A képek tárolása, de legfőképp azok adatbázisból történő visszakeresése nagyban különbözik a nem multimédiás jellegű egyéb adatok tárolásától és visszakeresésétől. Az újabb, objektumrelációs vagy teljesen objektumorientált szemléletű adatbázisok terjedésével pedig a problémákra újabb megoldási lehetőségek adódnak. Az adatbázisszerű megoldásokon túl az Interneten is egyre gyakrabban jelennek meg képarchívumok, melyekben a keresések még nem teljes mértékben tekinthetők megoldottnak. Persze az új technikák, technológiák megjelenése mellett a kérdés továbbra is megmaradt. Lehet-e pusztán a képi információk birtokában automatikusan képeket visszakeresni képarchívumokból? Létezik-e tartalomalapú képkinyerés?
1. Bevezetés
A minap egy Online
cikkadatbázisban kerestem egy cikk után. A gond az volt, hogy sem a
szerző, sem a cím nem jutott eszembe. A téma a képfeldolgozás egy témaköre
volt, és pontosan tudtam, milyen tesztképeket használtak a cikkben. Vajon
létezik módszer, mely segítségével pusztán a tartalmazott képek alapján
megtalálom a keresett cikket?
Jó lenne a választ annyival
lerendezni, hogy igen-e avagy sem. De ez sajnos nem ilyen egyszerű. A képi
adatbázisok, képarchívumok legfontosabb feladata a képek tárolása, és azok
visszakeresésének megoldása. Ebből beláthatóan a képek tárolása okoz
kisebb problémát. A visszakeresés az, amely egy nagyon fontos sarokpontját
képezi a képadatbázisok létrehozásának [1] [4] [8] [13] [17].
2. A
képarchívumokról
Először tekintsük csak
át, miért lehet szükség a szöveges információk mellet képi információk
tárolására is. Az egyik ok, amikor a képi információ csak kiegészítő
szerepet játszik az archívumban, csak arra szolgál, hogy – úgymond –
kelendőbbé tegye a szöveges árút. Tipikus ilyen példa az újságok hirdetési
rovataiban megjelenő képes hirdetések, mikor az eladandó autó hirdetése
mellé prezentálnak egy amúgy sem jól kivehető fotót. Ez a webes
hirdetésekben, a webes archívumokban is egy jellemző eset. Erre élő példa egy napjainkban
működő magyar webes antikvárium, mely tartalmaz fotót a könyv
borítójáról is. A második csoportba azok az esetek sorolhatók, amikor már a kép
nem csak mint kiegészítő információ van jelen, hanem maga a kép képezi az
archívum tárgyát. Azért jött létre maga az adatbázis, hogy a képet, mint
információt tárolja. Ez alatt azt kell érteni, hogy a kép nem csak mint adat,
mint bitek sorozata van jelen, hanem mint információ is, azaz a tartalmazott
objektumokról is rendelkezünk valamilyen ismerettel. Még hétköznapibb nyelven
mondva, a kárpitos textiladatbázisát átnézve, a képek mellett pontosan szerepel
az, hogy az adott képen milyen színű, milyen anyagú, milyen árú textília
látható. És persze egyértelmű, hogy maga a kép a fontos, hiszen az alapján
választjuk ki, milyen bútorkárpitot szeretnénk, és az ár csak másodlagos (jó
esetben). A harmadik csoport a maradék, azaz amikor csak maguk a képek vannak
jelen az archívumban, és nincsen mellettük semmiféle kiegészítő információ
(tipikus példa erre a konferenciákon készült képállományok weblapra
történő felhelyezése, vagy képfeldolgozási körökben a tesztképek
publikálása).
Az itt megemlített osztályok
esetében persze még nem volt szó a visszakeresésről. Az első
csoportnál triviális a keresés iránya, a megadott szöveges információkhoz
szeretnénk a hozzá tartozó képet vagy képeket megkapni. A második csoport
esetében ez szintén kijelenthető (például egy festményadatbázisban megadom
a festőt, és szeretném látni a hozzá tartozó képeket), de már (a kép
fontosságából adódóan) felmerül egyéb jellegű keresés is, azaz mikor
megadom magát a festményt, és szeretném a hozzá tartozó adatokat (festő,
kor, méret) megkapni. Itt jelenik meg tehát az igény a vizuális információ
tartalom alapú kinyerésére. A harmadik eset úgymond a legkacifántosabb. Nincs
szöveges információ, amit meg szeretnénk kapni. Magát a képet akarjuk megkapni,
mert vagy csak részletei vannak meg, vagy rendelkezünk a képpel, de
kisebb/rosszabb minőségben. Ebben
a cikkben ez utóbbi két eset közös részeivel foglalkozom. Tehát nem azt
tekintjük most keresési iránynak, hogy szöveges információk alapján keresem a
képet és a többi hozzátartozó szöveget, hanem egy kép alapján keresek hasonló
képet, képeket, kapcsolódó szövegeket. Ha belegondolunk, korántsem triviális, hogy
ez hogyan oldható meg.
A
választ a vizuális információ tartalom alapú kinyerése adja [8]. Képzeljük el,
hogy tervezőként dolgozunk a következő Gyűrűk Ura epizódon.
Több ezer képet, grafikát és fotót lapozunk át a monitorunkon. Persze az
emlékeinkben csak néhány jellegzetességet tudunk felidézni ezekből a
képekből (az egyiken szép kék volt az ég, vagy homokdűnék voltak
rajta valahol, stb.). Hogyan találjuk meg a vizuális hasonlóságokat? Vagy ha
újságírók vagyunk, és az a feladatunk, hogy hasonlítsuk össze az újév
ünneplésének formáit a földön, hogyan találjuk meg a megfelelő videó képsorokat?
A vizuális információ kinyerés (Visual Information Retrieval, VIR) az ilyen
vizuális hasonlóságok kinyerésére fókuszál.
A tartalom alapú képkinyerés (Content-Based Image Retrieval, CBIR) pedig
kifejezetten a képi információk alapján történő kinyerést célozza meg.
Tekintsük át most nagyvonalakban, milyen eszközöket használnak a CBIR
rendszerek [13].
Ha
szöveges magyarázat is kapcsolódik a képekhez, akkor akár direkt, kulcsszó
alapú keresések is elvégezhetők. Mindazonáltal számos szituációban a
szöveges leírás vagy nem létezik, vagy nem teljes, és mint említettem, ez a
cikk nem az ilyen jellegű keresésekkel foglalkozik. Ha a szöveges leírás
nem elérhető, akkor a tartalomalapú képkinyerés felé kell fordulnunk. A
tartalomalapú megközelítések esetében a keresés olyan tulajdonságokon alapszik,
melyek közvetlenül a nyers képekből lettek kinyerve, mint például szín
vagy textúra. A meghatározó VIR paradigmák keresései három fő csoportba
oszthatók. Ezek a hasonlókép-alapú lekérdezések [11], a vázlat alapján
történő lekérdezések [3] [9], illetve az ikon alapú lekérdezések [8]. A
hasonló kép alapján történő lekérdezések esetében a felhasználó kiválaszt
egy képet, majd a rendszer visszaadja képek egy olyan sorozatát, melyek
hasonlóak a felhasználó által kiválasztott képhez. A vázlat alapú kereséseknél
a felhasználó manuálisan felvázol (rajzol) egy képet, mely a későbbiekben
a keresés alapja lesz. Az ikon alapúnál a felhasználó különböző ikonokat
helyez el a kép különböző pontjaiban, ezáltal kijelölve, hogy hol, milyen
vizuális tulajdonságot tart fontosnak [2]. Bármelyik megközelítési módot is
alkalmazzuk, a végeredmény az, hogy összeállítunk egy képet (mely plusz
információkkal is rendelkezik, mint például alkalmazandó illesztési stratégia,
stb.) és megkérjük a rendszert, a meghatározott feltételek mellett keressen
nekünk az archívumban olyan képeket, melyek kielégítik az általunk megadott
hasonlósági kritériumokat. Kérdés, mik ezek a hasonlósági kritériumok. És mi
az, hogy egyáltalán hasonlóság?
3. A
tulajdonságokról
Ahhoz,
hogy két képet összehasonlítsunk, a pixelről-pixelre történő
illeszkedésvizsgálat mellett számos kifinomultabb eszközt is alkalmazhatunk
(már csak a zaj miatt is). Az irodalomban használatos technikák mind
megegyeznek abban, hogy a képek totális összehasonlítása helyett a
képekből kinyert tulajdonságokat, tulajdonságvektorokat hasonlítják össze
[8]. A kinyerhető tulajdonságvektorokat két nagyobb csoportba szokás
sorolni [13]. Az első csoportba azok a vektorok tartoznak, melyekből a
kép kis hibával teljes mértékben visszaállítható. Ez a csoport a reprezentáció.
A másik csoportba azok a vektorok tartoznak, melyekből a kép nem állítható
vissza, de a kép, vagy a képen található objektumok valamilyen mérhető
tulajdonságait reprezentálják. Ezek a jellegzetességek. Az illesztések gyakran
mindkét fajta tulajdonságvektor meglétét is igényelik egy-egy hasonlóság
eldöntéséhez. A tulajdonságvektor szó mindkét osztály vektorait jelenti. Az
irodalomban legtöbbször csak a reprezentációt szokás külön nevesíteni, ha az szükséges.
Most először megnézzük, mik a legfontosabb tulajdonságok, majd azt
világítjuk meg, mit nevezünk hasonlóságnak ezek között a tulajdonságok között.
A
legelterjedtebb tulajdonságok a képen található színek (globális színek), a
képen található objektumok színei (lokális színek), az objektumok formái
(alakok), azok egymáshoz vett elhelyezkedései (struktúra), illetve az
objektumok felületi mintázatai (textúra). Az objektumok esetünkben olyan
egybefüggő régiókat jelentenek, melyek a környezetüktől homogén
színükkel és/vagy textúrájukkal elkülönülnek, úgymond foltokat alkotnak.
A
színek illeszkedésének vizsgálatában a leggyakrabban alkalmazott eszközök a
színhisztogrammok. A hisztogramm nem más, mint a képen, vagy a kép adott
régióján található pixelek színeinek eloszlása, tehát megadja, hogy egy adott
színt mennyi pixel realizál.

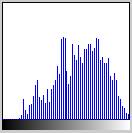
1. ábra: kép és hisztogrammja
Miután ezt az információt kinyertük a
képből, a hisztogrammok, mint eloszlások vizsgálata következik, hogy
megállapítsuk, a színek tekintetében hasonló-e a két kép, illetve régió. Az
irodalom számos hisztogrammtávolságot ismer, ezek közül következzen most
néhány. A példákban a két kép hisztogrammjai H0 és H1
vektorok, ahol H0(i)
értéke azon pixelek száma, melyek az i
sorszámú színnel rendelkeznek.
L1 távolság: d(H0,H1) = Si|H0(i)-H1(i)|
L2 távolság: d(H0,H1) = (Si|H0(i)-H1(i)|2)1/2
Li távolság: d(H0,H1) = maxi(H0(i),H1(i))
Az
alakok illeszkedésének vizsgálatához több megközelítési módot is lehet
alkalmazni. Egyesek a régiót egy ponthalmaznak tekintik, és két régió alakjának
illeszkedése esetén egy olyan leképezést keresnek, mely a két ponthalmaz
pontjait egymásnak jól megfelelteti. Mások hasonlóan járnak el, de nem a
különálló pontoknak tekintik a régiókat, hanem egymáshoz szorosan
kötődő pontoknak, foltoknak, és az alakok egymáshoz viszonyított
lefedését vizsgálják, illetve különféle olyan geometriai transzformációkat
keresnek, melyek minél kisebb deformációval viszik át az egyik foltot a
másikba. A legkifinomultabb módszerek az objektumok kontúrjait tekintik
kiindulási alapnak, és azokat, mint (zárt vagy nyílt) görbéket próbálják
egymásnak megfeleltetni különféle approximációs technikákkal. Az objektum
kontúrja persze nem csak paraméteres görbeként adható meg, hanem léteznek
különféle kontúrkódolási technikák is (lánckód, differencia kód, alakszám),
melyek jól alkalmazhatók.
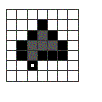
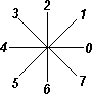
2. ábra: objektum rögzített kiindulási ponttal, és az iránykódok. A lánckód: 1002335567
A lánckód végül is nem más, mint az adott
görbét leíró pixelek sorozatának egymáshoz viszonyított elhelyezkedéseinek a
leírása. A [6]-ban ilyen, lánckóddal megadott kontúrok hasonlóságvizsgálatára
találhatunk példát.
Az
objektumok egymáshoz viszonyított elhelyezkedésének vizsgálata a már korábban
említett ikon alapú kereséseknél is jól alkalmazható. Gyakori, hogy a képet egy
valamilyen méretű mátrixnak tekintik, ahol a mátrixban található elemek az
objektumok (immár mértüktől függetlenül), és a mátrixok között próbálnak
meg olyan transzformációt végrehajtani, melyek az egyikből a másikat adják
eredményül.
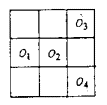
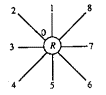
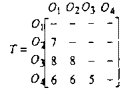
3.
ábra: szimbolikus kép, a 9DLT kódok és maga a 9DLT mátrix
Egy
másik megközelítési mód az, amikor egy úgynevezett 9DLT (9 Direction Lower
Triangular, 9 irányítású alsó háromszög) mátrixot építenek fel mindkét képre,
és azon mátrixokat főkomponens analízissel [2], vagy egyéb statisztikai
eszközökkel vizsgálják tovább.
A
textúrák illeszkedésének vizsgálata az egyik legbonyolultabb feladat, ugyanis
már magának a textúrának a definíciója is problémákba ütközik. A textúra egy
nagyon intuitív fogalom. Minden gyerek tudja, hogy a leopárd pöttyös, de a
tigris csíkos. Ebből a példából is látszik, hogy a textúra az valamilyen
intenzitások és színek ismétlődése. No persze ez csak egy megközelítés. A
textúrát (vizuális textúrát) befolyásolja az anyag fizikai felülete is (érdes,
tükröződő, stb.). Érződik az intuitív megközelítés, ugyanis a
textúrát pontosan definiálni meglehetősen nehéz (ez abból is látszik, hogy
már számos eltérő definíciója létezik az irodalomban). Az univerzális
textúra definíció hiányától eltekintve minden kutatás megegyezik néhány közös
pontban. Ezek, hogy egy adott textúrán belül fontos a pixelintenzitások
változását követni az egymáshoz közel álló pixeleken, azaz limitált a felbontás
alulról ilyen értelemben, másrészt a skálázás is közrejátszik a textúrában,
mert más-más skálázás esetén mást lehet ismétlődőnek tekinteni (azaz
limitált a felbontás felülről is).



4.
ábra: különféle textúrák
Mikor különböztethető meg két textúra,
ha ugyanazokkal a fényerő, kontraszt és szín tulajdonságokkal
rendelkeznek? Ha beágyazzuk az egyik textúrát a másik textúrába, és a
beágyazott vizuálisan elüt a befogadótól, akkor a két textúra nem
tekinthető hasonlónak. Ennek eldöntése érdekében különféle statisztikai
eszközöket szokás alkalmazni, például Fisher féle kulcsokat, illetve Markov
véletlen mezőket, vagy egy másik megközelítés, amikor faautomatákkal generálnak
és ismertetnek fel textúrákat.
4. A
hasonlóságról
Most,
hogy láttuk, milyen tulajdonságokat szoktak kinyerni a képekből, felmerül
a kérdés, hogyan mérhető köztük a hasonlóság [8] [13]. Két megközelítési
mód terjedt el. Az egyik a hasonlóság mértékét egy 0 és 1 közötti valós számnak
tekinti, ahol az 1 a totális illeszkedés, míg a 0 a totális különbözőség.
A másik megközelítés pont fordítva osztályoz. A hasonlóságot távolságnak
tekinti, és ekkor annak értéke 0, ha a két kép (tulajdonság) identikus, és a távolság
egyre nagyobb, minél kisebb a hasonlóság. Melyik a jó megoldás? Mivel a
gyakorlatban a képek és azok tulajdonságainak univerzuma véges, így a két
megközelítési mód kisebb-nagyobb munkával jól megfeleltethető egymásnak. A
távolságok esetében a leggyakrabban megkívánt tulajdonságok a következők:
p1: d(I,I) = d(J,J) önhasonlóság
p2: d(I,I) £ d(I,J) minimalitás
p3: d(I,J) = d(J,I) szimmetria
p4: d(I,J) £ d(I,K) + d(K,J) háromszög egyenlőtlenség
Persze fontos megemlíteni, hogy ezek egyrészt
nem mindig biztosíthatók (például hogyan értelmezzük a háromszög
egyenlőtlenséget az emberi szem érzékelésére, vagy az emberi agy
hasonlóságfogalmára?), másrészt az alkalmazások tekintetében nem is biztos,
hogy mindegyiket biztosítani kell. Általánosan elfogadott, hogy a hasonlósághoz
minimálisan szükséges tulajdonságok a p1
és a p2, melyekhez az
egyszerűség kedvéért gyakran beveszik a p3-at.
5. A
keresésről
Miután tisztáztuk a
legfontosabb tulajdonságokat és a hasonlóság fogalmát, tekintsük át egy
általános keresés menetét. A felhasználó egy (hasonlókép-, vázlat- illetve
ikonalapú) interfészen keresztül meghatározza a keresőképet, azaz azt a
képet, amelyhez hasonlót keres az archívumban. Ezt jelölhetjük Q-val. Ezután a rendszer képezi a
keresőkép tulajdonságvektorait, majd sorra illeszti őket az
archívumban található képek vektoraira. A visszaadandó eredményhalmaz általában
három csoportra osztható. Van amikor csak egyetlen egy totálisan
illeszkedő képet keresünk (pontosabban a hozzá tartozó információkat). Ekkor
alkalmazzuk az identikus keresést, azaz azokat a R képeket, amelyekre
d(R,Q)
= 0.
Megadhatunk egy e környezetet is (küszöb),
ekkor azokat az R képeket keressük ahol
d(R,Q)
< e.
Ez az e-keresés. A harmadik
csoportba a legközelebbi szomszéd keresése (NN, Nearest Neighbour) tartozik,
ekkor azokat az R-eket keressük
melyekre
"P, P ¹ R, d(R,Q) £ d(P,Q).
Miután az eredményt illetve
eredményeket megkaptuk, a tanulási funkcióval rendelkező rendszerek
gyakran várnak egy visszacsatolást, melyben a felhasználó értékeli, esetleg
sorba rendezi a kapott eredményeket "jóságuk" szerint, így a rendszer
megpróbál pontosabb eredményt produkálni a következő ugyanilyen
jellegű kereséskor. A mi szempontunkból most igazán a keresés középső
fázisa az érdekes. Mi történik akkor, ha az archívum mérete meghalad egy
bizonyos határt, és a vektorok illesztésének teljes ideje olyan nagyra nő,
hogy a felhasználó nem bírja kivárni. Természetesen csökkenteni kellene
valahogy az illesztésre kandidált képek (vektorok) számát. Erre alkalmasak a
különféle multimédiás indexelési technikák.
6. Az
indexelésről
A multimédiás indexelési
technikák két nagy csoportba oszthatók [5] [7]. Az első az adatpartíciós
indexelés, a másik pedig a térpartíciós indexelés. Az első az adatok eloszlása
alapján, a másik pedig előre meghatározott vonalak mentén osztja fel a
teret, függetlenül az adatok előfordulásától. A térpartíciós indexelés nem
túl hatékony azon esetekben, mikor a képek közel azonosak, azaz az indexeik
távolsága nem túl nagy, és egy nagyobb csoportba csoportosulva nem töltik ki az
elméleti teret. Ilyen esetek elkerülése érdekében érdemesebb az adatpartíciós
indexelést alkalmazni.
Az adatpartíciós indexelés
az R-fából származtatható [18], mely eredetileg kétdimenziós adatok indexelésére
szolgált a GIS-ben (Geographic Information System). Később az R-fákat
kiterjesztették többdimenziós adatokra is. Az SS-fa például egy ilyen
kiterjesztés. De nagyon sok egyéb kiterjesztés is létezik, melyek mind azon
alapulnak, hogy nem minden régiónak van ugyanakkora szerepe a
visszakeresésekkor.
Amennyiben a multimédiás
indexelési technikákat kiegészítjük a könyvtári rendszerekben használatos
szöveg alapú indexelési technikákkal, egy jól működő, többszörös
indexelési technikát lehet kialakítani, mely egyszerre támogatja a szöveges
információ hasonló kép alapján történő elérését, illetve a képek szöveges
információ alapján történő keresését.
7. A
kutatási területekről
Az
eddigiekben láthattuk, hogyan épülnek fel a képarchívumok tartalomalapú
keresőrendszerei, vizuális információ kinyerő moduljai. Most pedig
tekintsük át, milyen lehetséges kutatási területek vannak a témában. Ha röviden
akarnám kifejezni magam, azt mondhatnám, hogy bármi, hiszen a technológia még
eléggé gyerekcipőben jár.
Elsőként
a gépi látás az, ami előbbre viheti a témát. Ugyanis ha nem pusztán
robotikusan működő illesztőalgoritmus-gyűjteményt akarunk
alkalmazni, akkor nagy előrelépést hozhat a különféle gépi látást
alkalmazó, illetve mesterséges intelligencia algoritmusokkal együttműködő
felismerő rendszerek használata (arcdetektálás, arcfelismerés,
karakterfelismerés, stb.). No persze, ez a távoli jövő. Adott speciális
feladatok esetén az illesztőalgoritmusok javítása is nagy előrelépést
hozhat. A régiók alakjának illesztésében például azt feltételezve, hogy a
kontúrt leíró lánckódok különféle valószínűségi változók mintarealizációi,
statisztikai próbák alkalmazására nyílik sor [6]. Hasonlóan jó eredményre
vezet, ha a lánckódot egy sztochasztikus folyamat egy realizációjának tekintjük.
Az
indexelés területén is lehet előrelépéseket tenni [16]. Köztudott, hogy a
visszakeresés illetve a karbantartás (beleértve a bővítést is) minden
adatszerkezet esetén szöges ellentétben áll egymással. Minél gyorsabb illetve
könnyebb a visszakeresés, annál nehezebb a karbantartás, illetve annál több
feladatot kell ellátni az archívum bővítése setén. Amennyiben az archívum
képein található objektumok jól csoportosíthatók, akkor a beszúráskor csak
annyi plusz feladatot kell ellátni a beszúrást végző személynek, hogy
meghatározza, mely csoportba tartozik az ábrázolt objektum tekintetében a kép.
Az objektumorientált modellezés segítségével lehetségessé válhat olyan
osztályhierarchia felépítése, mely a generalizáció/specializáció segítségével
jól modellezi a képen ábrázolt objektumokat. Az így megkapott osztályhierarchia
pedig nem más, mint egy hierarchikus, többszintű indexszerkezet, mely a
szó legszorosabb értelmében tartalom alapú, ugyanis a képek tartalmán alapszik.
A hierarchia csomópontjai tartalmazhatják a konkrét képekre vonatkozó
indexbejegyzéseket. Ilyen jellegű keresésekkel [14]-ben és [15]-ben
bővebben foglalkozom.
Mint
már korábban említettem, napjaink illesztőalgoritmusai a képen található
régiókon alapulnak. Itt hatalmas előrelépéseket lehet tenni, ugyanis a
régiókijelölés egy olyan lépés, mely szinte sohasem működik jól.
Gondoljunk csak a sok textúrát tartalmazó képek régiókijelölésire. Ezen a
problémán is, illetve a régiók egymáshoz viszonyított helyzetén alapuló
keresésekben is nagyot segíthet az, ha a keresést indító személy nagyrészt be
tudja határolni, a kép mely részén érdemes keresni, és főleg, hogy mit
(lásd ikon alapú keresések). Ilyen irányban továbblépés az, ha megengedjük,
hogy a kereső személy összetett kereséseket indítson el (pl.: vagy kék
volt a kép teteje, vagy piros, de hogy a jobb alsó sarokban nem zöld, az
biztos). Egy ilyen jellegű kereséshez biztosítani kell a részképeken
alapuló keresést, illetve a keresési eredmények logikai eszközökkel
történő összekapcsolását (illetve maguknak a kereséseknek a
formalizációját). Erre láthatunk példát [14]-ben.
A
kérdésformalizáció a képadatbázisok lekérdezőnyelveiben is felmerül, így
több kutatás is foglalkozik a multimédiás adatbázisok lekérdezőnyelveivel,
melyek lehetnek SQL-alapúak illetve akár teljesen új alapra is
helyezhetőek (gyakori, hogy valamilyen algebrából vagy kalkulusból
indulnak ki) [10] [11]. A lekérdezőnyelvek pedig már nyitást képeznek az
archívumok (akár máselvű) interfészei felé, melyeken lehetőség nyílik
a felhasználó általi visszacsatolásra, amely segítségével a rendszerek
javíthatják válaszadó képességeiket (és ezáltal megint elértünk a mesterséges
intelligencián alapuló rendszerekhez).
Az eddigieket talán úgy
lehetne összefoglalni, hogy a kutatás alapjait alkotó kérdések a
következők: Mi a jobb, az alacsony szintű tulajdonságokon alapuló
keresések fejlesztése, vagy szemantikus megoldások kifejlesztése? Hogyan lehet
összekötni, fuzionálni a különféle lehetőségeket? Egymenetes
kérdésfeltevést érdemes választani, vagy végignavigálni a keresést a
megfelelő válaszig? Egyáltalán, az eddigi rendszerek továbbfejlesztésére
vagy teljesen új alapra helyezésére lenne-e szükség? És persze mindezen felül
ott van a teljesítmény fokozásának kérdése is, mint mindennel összefüggő probléma.
8. Az
alkalmazásokról
Számos alkalmazás létezik,
ahol nagy szerepe lehet a képi adatbázisoknak, a tartalomalapú képkinyerésnek
illetve tágabb értelemben a vizuális információkinyerésnek. Ilyenek például az
építészet, belső design, biokémia, kulturális szolgáltatások, Online
katalógusok, boltok, az oktatás, szórakozás, film-, kép-, videó archiválás,
azonosítás, GIS, újságírás, orvosi alkalmazások, távérzékelés, őrzés,
turista információk, és végül, de nem utolsó sorban az intelligens könyvtári rendszerek.
Építészetileg leginkább a
hasonló épületek, szerkezetek megtalálása lehet fontos, mely segítségével a
felhasználó egy vázlatot kaphat az épülő ház kinézetéről például. A
belsőépítészetben a szín alapú (illetve a szöveges leírás alapú) keresések
lehetnek kifizetődők (jók a színek, de milyen hasonló
színezetű/hangulatú kombináció lehetséges).
A biokémiában gyakori a
molekulák osztályozása, katalogizálása. Ezek indexelése nagy segítséget
nyújthat a gyógyszerek fejlesztésében. Gondoljunk csak arra, amikor a
felhasználó a mikroszkópban látott molekulához hasonló képű/alakú
molekulákat keres az archívumban. Ilyen esetekben az alak/szöveg alapú
keresések nyújtanak nagy segítséget.
Az Online vásárlás esetében
gyakori tapasztalat, hogy a vásárlók nem konkrét dolgot keresnek, hanem
"ha meglátom, felismerem" alapon böngésznek a termékek között. Itt is
nagy segítséget nyújthat például a szín alapú keresés.
Az oktatás szempontjából nem
csak a képfeldolgozás oktatása terén hasznosíthatók a VIR tulajdonságai, hanem
például akár a történelem oktatás területén, vagy a művészettörténet
oktatása terén is (arcok, képek, szobrok keresése).
A film, kép, videó
archiválást azt hiszem nem kell külön említeni, hiszen ehhez alkalmazkodik
leginkább a VIR, mert
természetéből ez az, ami a VIR egyik legfontosabb szerepe, az archívumokban
való hathatós keresés.
Az orvosi alkalmazásokban az
abnormális jelenségek vizuális felismerésén van a hangsúly. A vizuális alapot a
röntgen, MR, CT és egyéb képek szolgáltatják.
Az intelligens könyvtári
rendszerek esetében nem csak a könyvek borítóinak képeit kell képi
információnak tekinteni, hanem minden tartalmazott képet, illetve grafikát is
annak tekinthetünk. Így a könyvek és a cikkek által tartalmazott fotók és
grafikák is a keresés alapjait képezhetnék elősegítve a minél szélesebb
palettán történő kereséseket.
9. És
végül: a kérdésről
Zárszóként most már illene
megválaszolni a címben feltett kérdésemet, létezik-e tartalomalapú képkinyerés
képarchívumokból. A fentiek ismeretében sem lehet eléggé rövid választ adni. A
legdiplomatikusabb talán az, hogy jó lenne, ha lenne. Maga a paradigma létezik.
Láthattuk a téma sokszínűségét, szerteágazóságát. Rengetegen kutatnak,
fejlesztenek a témában. Tehát létezik, de azt is hozzá kell tenni, hogy nincs
igazán hatékonyan működő, mindenki által használható rendszer.
Elszigetelt prototípusok, vagy speciális feladatot ellátó zárt rendszerek
persze léteznek. De az, hogy cikkeket, könyveket vagy egyéb szöveges
információkat keressünk akár az Interneten hasonló képeken alapuló
keresésekkel, még csak álom. Tehát van kinyerés, mert foglakoznak vele,
fejlesztik, és nincs, mert nincs igazi működő alkalmazás. Azok a
képkeresők, amik széles körben, mindenki által elérhetőek, pedig
napjainkban még csak szöveges kereséseket támogatnak (lásd: Google
képkereső). Az irány tehát adott, már csak a megfelelően kiforrott
technológiai háttér szükségeltetik.
Hivatkozások
[1] C. C. Chang, S. Y. Lee, Retrieval of similar pictures on pictorial databases, Pattern Recogn. 24, 7, (1991), 675-681,
[2] C. C. Chang, T. C. Wu, An exact match retrieval scheme based upon principal component analysis, Pattern Recognition Letters, 16, (1995), 465-470
[3] M. Egenhofer, Spatial-Query-by-Sketch, VL'96, IEEE Symposium on Visual Languages, (1996), 60-67
[4] J. M. Fuertes, M. Lucena, N. Pérez de la Blanca, J. Chamorro-Martínez, A scheme of colour image retrieval from databases, Pattern Recognition Letters 22, (2001), 323-337,
[5] W. I. Grosky, R. Mehrotra, Index-based object recognition in pictorial data management, Comput. Vision Graph. Image Process. 52, 3, (1990), 416-436.
[6] J. Kormos, K. Veréb, Recognition of chain-coded patches, COMCON 8, Proceedings of 8th International Conf. on Advances in Communication and Control (Telecommunications/Signal Processing), (2001), 37-45
[7] E. A. El-Kwae, M. R. Kabuka, Efficient Content-Based Indexing of Large Image Databases, ACM Transactions on Information Systems, Vol. 18, No. 2, April (2000).
[8] M. S. Lew (ed), Principles of Visual Information Retrieval, Springer, (2001)
[9] S. Matusiak, M. Daoundi, T. Blu, O. Avaro, Scketch-Based Images Database Retrieval, MIS'98, LNCS 1508, (1998), 185-191
[10] J. Z. Li, M. T. Ozsu, D. Szafron, V. Oria, MOQL: A Multimedia Object Query Language, 3rd Int. Workshop on Multimedia Information Systems, Como, Italy, (1997), 19-28,
[11] D. Papadias, T. Sellis, A Pictorial Query-By-Example Language, Journal of Visual Languages and Computing, 6(1), (1995), 53-72
[12] N. Roussopoulos, C. Faloutsos, T. Sellis, An Efficient Pictorial Database System for PSQL, IEEE Trans. Soft. Eng. 14 (5), (1988), 639-650,
[13] S. Santini, Exploratory Image Databases, Content-Based retrieval, Academic Press, (2001)
[14] K. Veréb, Kutatási irányzatok az objektumorientált képadatbázisok terén, Informatika a felsőoktatásban, (2002), 975-981
[15] K. Veréb, Objektum alapú keresési és indexelési technológia képadatbázisokhoz, V. Országos Objektumorientált Konferencia, (2002), http://zenith.sch.bme.hu/~ooffk/oookea/Vereb_Krisztian.rtf
[16] S. F. Chang, Content based indexing and retrieval of visual information, IEEE Signal Processing Magazine 14, (4), (1997), 45-48,
[17] J. P. Eakins, Automatic image content retrieval: Are we going anywhere? In Proceedings of the 3rd International Conference on Electronic Library and Visual Information Research, May (1996)
[18] A. Guttman, R-Trees: A dynamic index structure for spatial searching. Proc ACM SIGMOD, Boston, MA, (1984), 47-57